The pattern is crap, for several reasons (see @peavine’s dissection of it for more detail).
This “match phone number” string is supposedly intended for international phone numbers. While a leading + sign is now often used to introduce a country prefix, there are still regions using 00 for that. And there are quite a few countries having three digit prefixes.
Assuming only spaces, dots and dashes as group separators as in [\s.-] is overly narrow – what about slashes?
It uses no capturing groups, as already pointed out by @peavine. So, it does not help in reformatting, only in matching.
And it, of course, only works for US phone numbers. Apparently everybody assumes those are the only relevant ones
@peavine is correct in their statement that the RE (?m)^(\d{3}).?(\d{3}).?(\d{4})$ works ok. However, they’re missing a backslash in front of the dots, perhaps because Discourse requires two of those outside code. As it stands now, this RE will match anything between \d{3}, '\d{3}and\d{4}`. For example, 123456789011 would also match and be rewritten as (123) 567-9011.
Also: I posted a modified JavaScript solution in the other thread. It handles both formats in any number of columns (and has two glitches):
chrillek. Thanks for making note of this. When I posted this yesterday the pattern did have backslashes before the dots but apparently the forum software deleted them. I’ve edited the post to display the pattern as a script, which retains the desired backslashes. I retested the pattern and it matches 1234567890 and 123.456.7890 but not 12345678901
@pavilion. I reviewed and retested my script in post 67, and it works as expected under every circumstance I could envision. The only exception is when one of the cells in a target column had been merged with another cell. Sorry I couldn’t help.
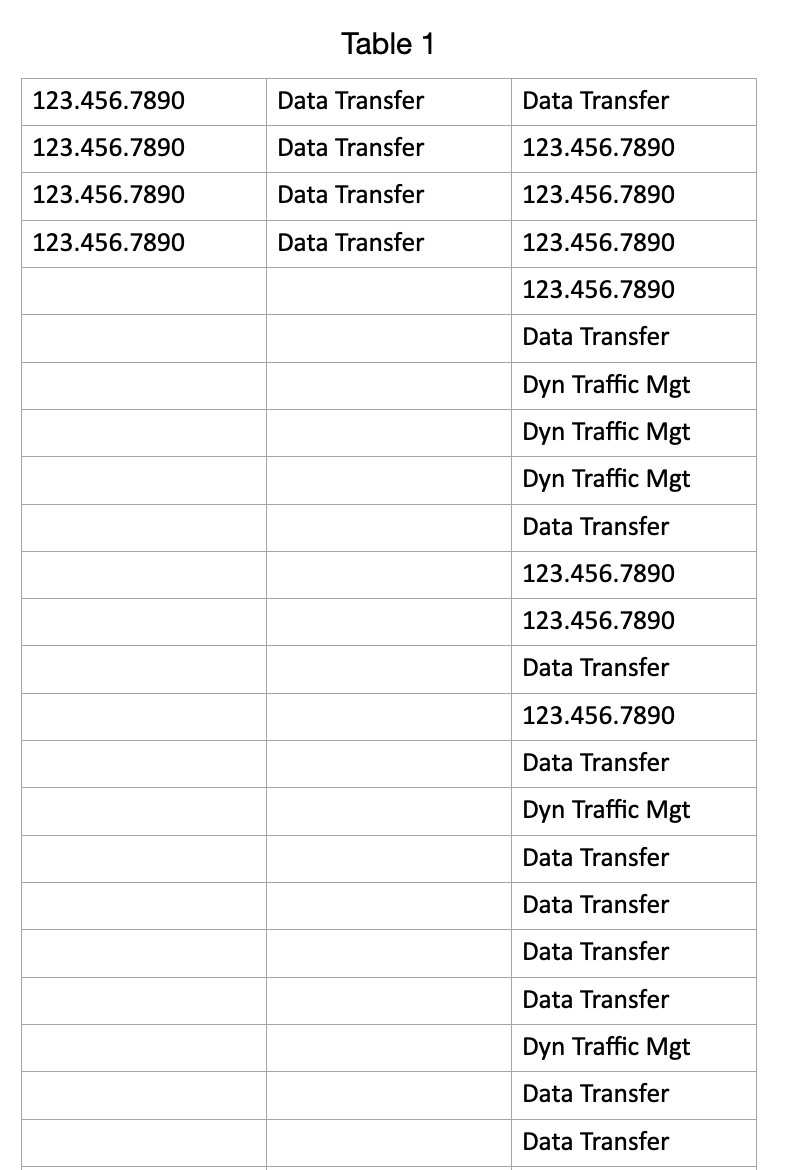
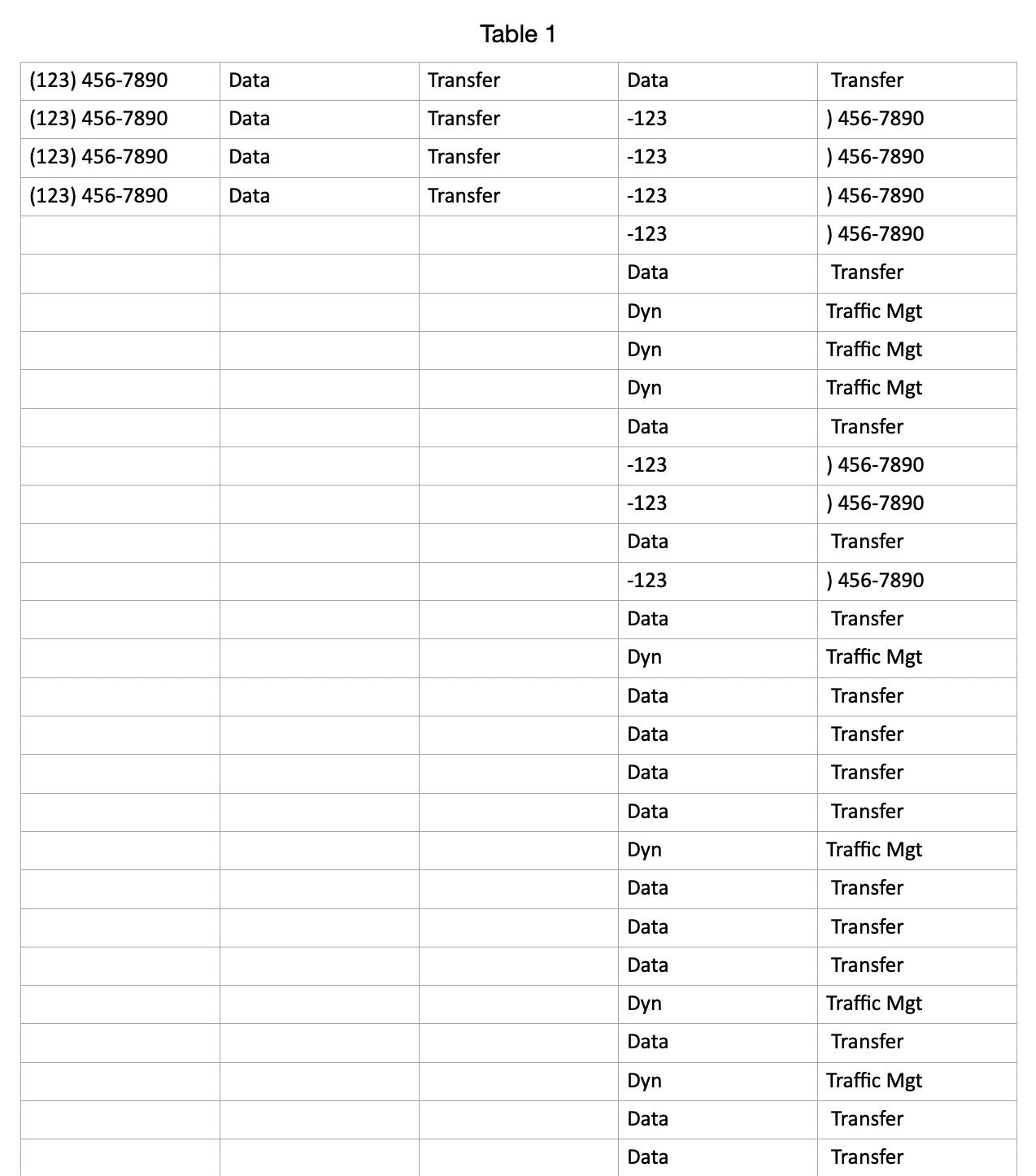
Everything I’ve tried still leaves me with the same results as my earlier screenshots, with the data being truncated after the space into the next column. Can’t understand how the two of us are getting different results from the same formula. And moreover, if the issue is just the regex syntax, at worst wouldn’t it just not recognize the number and skip it, and not recognize the text and skip it? I thought the regex is just to be able to identify what cells get processed and what cells get ignored. But here, both the text and the 123.456.7890 are getting identified and just being mis-processed, no?
OK, well here’s something to ponder and hopefully help me. I tried something different and now it works.
I copied 5 cells of each phone number column from the original sheet and pasted by themselves into a brand new sheet with no other data, and the script as you last posted it worked perfectly. But somehow when the script runs on the full spreadsheet it doesn’t.
Not sure why this is happening?
UPDATE: Not so fast. After I copied the entire columns over, the problem reappeared. I am going to see what there might be in that second column causing the issue and report back.
Appreciate your input tremendously. After testing this again my spreadsheet the issue is not the 123.456.7890 number format at all because when I isolate all the numbers from the column it works as expected. The problem is the text, and a simply test will show it to you. Please run the script on a column of two cells with text that contains more than one word, e.g. A1- Text Message, A2 = Data Message and then you’ll see what I’m experiencing on the full column. But what made this harder to understand is that once the column contains both types, the numbers and the multi-word text, then ALL the entries are formatted badly, not just the text.
OK, here’s the issue. the 123.456.7890 format in the second column gets processed perfectly by your script when there is not text in other cells (or more specifically, text with a space between words). Once there are those types of cells in the column, the whole thing gets formatted badly.
As a test, run your script on a column of cells with two words in them and you’ll see exactly what I mean.
UPDATE: That’s not exactly right either. I am uploading a very simple test spreadsheet, if you could kindly run the script on each of the columns and let me know if you can makes heads or tails of what’s going on!
I’d been under the impression up till now that each column contained its own type of data and that column “B” only contained US-style telephone numbers.
If a cell has a space in it, the text is going to be split into separate cells when pasted back, in the same way the reformatted phone numbers were before the space in them was replaced with a non-break space. An extra line needs to be inserted into peavine’s script, just before the clipboard’s set, to replace every space in the entire text with a non-break space:
set theString to (theString's stringByReplacingOccurrencesOfString:space withString:(character id 160) options:1024 range:{0, theString's |length|()})
But I don’t know why normal spaces are confusing Numbers here.
Just a wild guess: Numbers is tearing pasted data as it is a text file that is told to read. Therefore, it tries to find a „separator“ like comma, semicolon or tab. In their absence, it considers a space to be the separator. Adding a comma to the end of the first line fixes this behavior. I think.
Yes. I think you’re right. I’ve just been testing with my multi-column script here and it works perfectly if I change the non-break spaces back to ordinary spaces because it uses tabs as the column separators.
One more thing: Appending a comma to the first line before setting the clipboard values seems to fix all the issues. And it’s bloody simple to fix this first line after pasting…
The only grievance I have are the completely useless calls to display(). That is, they’d be useless if Apple’s stuff were working sanely.
/* Anonymous, autoexecuting function to do the work */
(() => {
/* Set up some constants:
- the columns to search/replace in 'columnIndices' ('A' is 0, 'B' is 1 etc)
- the 'app' constant (like the tell block in AS)
- the table to work with
- the regular expression to find values that have to be modified
- the regular expression to match the phone numbers
- the replacement string to change the phone numbers
- and the 'currentApplication' which is needed (?) to work with the clipboard
*/
const columnIndices = [0,2]; // Select columns A and C
const app = Application("Numbers");
const table = app.documents[0].sheets[0].tables[0]; //in 1st doc: 1st table's 1st sheet
const testRE = /^[0-9.]{10,12}$/; //rows of 10 to 12 characters only containing digits and dots
const dateRE = /^(\d{3})\.?(\d{3})\.?(\d{4})$/; //phone numbers with and without dots
const replaceString = "($1) $2-$3"; // correctly formatted phone numbers
const ca = Application.currentApplication();
ca.includeStandardAdditions = true;
/* Loop over the columns in 'columnIndices */
columnIndices.forEach(c => {
const currentCol = table.columns[c];
/* Get all values for the current column. That is an 'Array' in JavaScript */
const vals = currentCol.cells.value();
/* Loop over the values and create a new 'Array' containing
- the unmodified originals for any undefined/empty values or those not matching the 'test' condition
- the corrected phone numbers
*/
const newVals = vals.map(v => {
if (!v || ! testRE.test(v)) return v;
const nv = (v+"").replace(dateRE, replaceString);
return nv;
});
/* Set the clipboard to a newline separated string. Append a comma to the
first line to stop Numbers from treating the phone numbers as strings
*/
ca.setTheClipboardTo(newVals.join('\n').replace('\n',',\n'));
app.activate();
/* Set the selection for the table */
table.selectionRange = currentCol;
delay(0.3);
/* Send the "paste without format" keystroke */
const se = Application('System Events');
se.keystroke('v',{using: ["shift down", "option down", "command down"]});
delay(0.3);
/* fix the first row */
currentCol.cells[0].value = newVals[0];
})
})()
I’m sure some kind soul can recreate this in AppleScript if they need it.
@pavilion. Thanks for the test spreadsheet, which allowed me to reproduce the issue.
I tested Nigel’s suggestion, which seemed to fix the issue with my script. Also, I found a line of my script that could cause a problem (not related to the current issue), and I have fixed that also. So, my suggestion for testing is:
use framework "Foundation"
use scripting additions
-- formatColumn("A")
-- delay 5 -- test lower values
-- formatColumn("B")
-- delay 5 -- test different values
formatColumn("C")
on formatColumn(theColumn)
tell application "Numbers" to tell table 1 of sheet 1 of document 1
set format of column theColumn to text
set theValues to value of every cell in column theColumn
set selection range to range (theColumn & "1:" & theColumn & "1")
end tell
set theArray to current application's NSArray's arrayWithArray:theValues
set theString to theArray's componentsJoinedByString:linefeed
set thePattern to "(?m)^(\\d{3})\\.?(\\d{3})\\.?(\\d{4})$"
set theString to (theString's stringByReplacingOccurrencesOfString:thePattern withString:("($1)" & character id 160 & "$2-$3") options:1024 range:{0, theString's |length|()})
set thePattern to "(?m)^<null>$"
set theString to (theString's stringByReplacingOccurrencesOfString:thePattern withString:"" options:1024 range:{0, theString's |length|()})
set theString to (theString's stringByReplacingOccurrencesOfString:space withString:(character id 160) options:1024 range:{0, theString's |length|()})
set the clipboard to (theString as text)
delay 0.2 -- test different values
tell application "System Events" to tell process "Numbers"
set frontmost to true
click menu item "Paste" of menu "Edit" of menu bar 1
end tell
end formatColumn
Works like an absolute charm! So appreciative for all your help (as well as @chrillek) and hope others in need of the same solution will find this super useful.
p.s. I assume there’s nothing left to tweak in the script to make it any faster?
Sounds right, and was something I also saw earlier that when you add a comma after the first cell, it formats more reliably. Thanks for the great suggestion that got this working right!
Why would adding more code make it run faster? And why is speed so important? Did you test the script I posted for speed? I have hunch that it might be faster than the AS stuff, but I’m not sure.
My sense from your comment was that adding the comma at the start and then removing it later would make the script more efficient and thus run faster, which is just something I assume is always better than slower, so I thought it might make sense to compare how the two versions run side by side.
@pavilion. I don’t know of any way to make the code itself faster. If you are formatting multiple columns at once, you could try reducing or eliminating the 5-second delays. And, if the columns are adjacent, you could rewrite the script to format adjacent columns in one pass of the handler, although that might be more work than it’s worth.
BTW, I ran a timing test and it takes my script 350 milliseconds to format column C of your test spreadsheet. Of this amount, only 15 milliseconds is spent formatting data, and the rest is attributable to Numbers doing its work. Unless you take an entirely different approach, I don’t know of a way to make Numbers faster.